Java 线程池
什么是线程池
前言
大家可能都听说过线程池、连接池、内存池、对象池等。那究竟这些池到底是什么呢?
其实就是一种池化技术,就是提前保存大量的资源,以备不时之需。在机器资源有限的情况下,使用池化技术可以大大的提高资源的利用率,提升性能等。
所谓的线程池也是池化技术的一种具体实现。下面将以线程池为例做总结。
创建一个线程
Java创建一个线程通常有两种方法,一种是实现Runnable接口,另一种是继承Thread类。还有两种是衍生的方法,一种是通过Callable和FutureTask创建线程,另外一种是通过线程池创建线程。
下面以实现Runnable接口为例,做说明。
public class App {
public static void main(String[] args) throws Exception {
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("线程运行中");
}
}).start();
}
}
新线程被创建了之后就可以利用多核CPU,处理更多线程了。当一个任务结束后,当前线程就回收。
但很多时候,我们不止会执行一个任务。如果每次都是如此的创建线程->执行任务->销毁线程,会造成很大的性能开销。
那能否一个线程创建后,执行完一个任务后,又去执行另一个任务,而不是销毁。这就是线程池。
这也就是池化技术的思想,通过预先创建好多个线程,放在池中,这样可以在需要使用线程的时候直接获取,避免多次重复创建、销毁带来的开销。
线程池的简单使用
Java创建线程池
import java.util.concurrent.*;
public class App {
public static void main(String[] args) throws Exception {
ExecutorService executorService = new ThreadPoolExecutor(1, 1,
60L, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(10));
executorService.execute(new Runnable() {
@Override
public void run() {
System.out.println("线程池");
}
});
executorService.shutdown();
}
}
通过上面代码不难理解,Java创建线程池很简单,直接通过JDK提供的ThreadPoolExecutor构造就可以。也可以通过Executors静态工厂构建,但一般不建议。
线程池构造函数
ThreadPoolExecutor部分源码展示
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
如果把线程池比作一个公司。公司会有正式员工处理正常业务,如果工作量大的话,会雇佣外包人员来工作。
闲时就可以释放外包人员以减少公司管理开销。一个公司因为成本关系,雇佣的人员始终是有最大数。
如果这时候还有任务处理不过来,就走需求池排任务。
-
acc : 获取调用上下文
-
corePoolSize: 核心线程数量,可以类比正式员工数量,常驻线程数量。
-
maximumPoolSize: 最大的线程数量,公司最多雇佣员工数量。常驻+临时线程数量。
-
workQueue:多余任务等待队列,再多的人都处理不过来了,需要等着,在这个地方等。
-
keepAliveTime:非核心线程空闲时间,就是外包人员等了多久,如果还没有活干,解雇了。
-
threadFactory: 创建线程的工厂,在这个地方可以统一处理创建的线程的属性。每个公司对员工的要求不一样,恩,在这里设置员工的属性。
-
handler:线程池拒绝策略,什么意思呢?就是当任务实在是太多,人也不够,需求池也排满了,还有任务咋办?默认是不处理,抛出异常告诉任务提交者,我这忙不过来了。
添加一个任务
接着,我们看一下线程池中比较重要的execute方法,该方法用于向线程池中添加一个任务。
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) { // 第一个
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) { // 第二个
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false)) // 第三个
reject(command);
}
第一个判断:workerCountOf方法根据ctl的低29位,得到线程池的当前线程数,如果线程数小于corePoolSize,则执行addWorker方法创建新的线程执行任务;
第二个判断:判断线程池是否在运行,如果在,任务队列是否允许插入,插入成功再次验证线程池是否运行,如果不在运行,移除插入的任务,然后抛出拒绝策略。如果在运行,没有线程了,就启用一个线程。
第三个判断:如果添加非核心线程失败,就直接拒绝了。
添加worker线程
从方法execute的实现可以看出:addWorker主要负责创建新的线程并执行任务,代码如下(这里代码有点长,没关系,也是分块的,总共有5个关键的代码块):
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
这段代码是做是否能够添加工作线程条件过滤: 判断线程池的状态,如果线程池的状态值大于或等SHUTDOWN,则不处理提交的任务,直接返回;
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
这段代码是做做自旋,更新创建线程数量: 通过参数core判断当前需要创建的线程是否为核心线程,如果core为true,且当前线程数小于corePoolSize,则跳出循环,开始创建新的线程
有人或许会疑问 retry 是什么?这个是java中的goto语法。只能运用在break和continue后面。
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
上面代码获取线程池主锁。 线程池的工作线程通过Woker类实现,通过ReentrantLock锁保证线程安全。
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
上面代码添加线程到workers中(线程池中)。
if (workerAdded) {
t.start();
workerStarted = true;
}
上面代码启动新建的线程。
看完了上面的代码,估计大家还有一个疑问,workers是什么? 看看源码就知道其实是一个hashSet。所以,线程池底层的存储结构其实就是一个HashSet。
private final HashSet<Worker> workers = new HashSet<Worker>();
worker线程处理队列任务
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock();
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) { // 第一处
w.lock();
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task); // 第二处
Throwable thrown = null;
try {
task.run(); // 第三处
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown); // 第四处
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
-
第一处:是否是第一次执行任务,或者从队列中可以获取到任务。
-
第二处:获取到任务后,执行任务开始前操作钩子。
-
第三处:执行任务。
-
第四处:执行任务后钩子。
这两个钩子(beforeExecute,afterExecute)允许我们自己继承线程池,做任务执行前后处理。
到这里,源代码分析到此为止。
总结
-
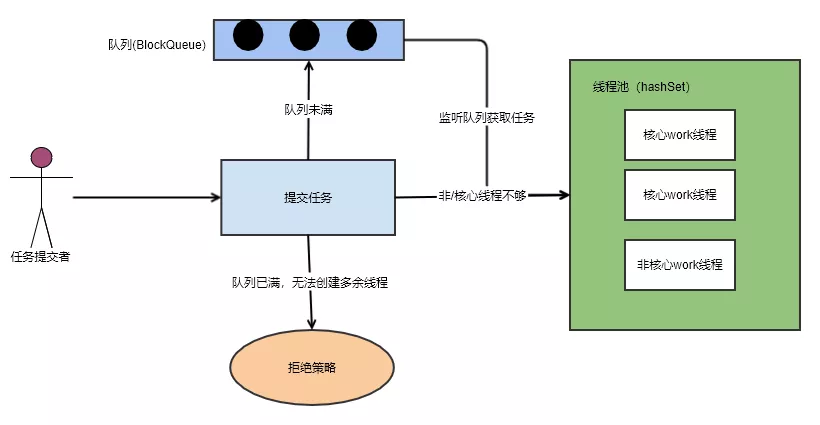
所谓线程池本质是一个hashSet。多余的任务会放在阻塞队列中。
-
只有当阻塞队列满了后,才会触发非核心线程的创建。所以非核心线程只是临时过来打杂的。直到空闲了,然后自己关闭了。
-
线程池提供了两个钩子(beforeExecute,afterExecute)给我们,我们继承线程池,在执行任务前后做一些事情。
-
线程池原理关键技术:锁(lock,cas)、阻塞队列、hashSet(资源池)
 声明
转载自 https://mp.weixin.qq.com/s/-89-CcDnSLBYy3THmcLEdQ
声明
转载自 https://mp.weixin.qq.com/s/-89-CcDnSLBYy3THmcLEdQ
如果觉得对你有帮助,我就没白写,如果需要交流,可以留言,或者加我wx
